Несинхронный Python

Введение
В арсенале современного программиста есть множество средств для создания не синхронного кода (выполняемого не последовательно).
Серебряной пули среди этих инструментов нет, надо выбирать под конкретную задачу.
В этой статье я сделаю краткий обзор, который позволит вам осознанно делать этот выбор.
Термин “не синхронный” я использую потому, что хотел бы поговорить о всем многообразии методик, а не только, например, о многопоточности.
Типы задач, требующие несинхронного кода
Много ввода-вывода
В современных компьютерах существенно отличается скорость процессора и скорость подсистем ввода-вывода. К подсистемам ввода-вывода в первую очередь относятся файлы на диске и сетевые соединения.
Допустим, вы пишете веб-сервер, обрабатывающий запросы.
Клиент устанавливает TCP-соединение с вашим сервером, после чего начинает отправлять вам в рамках этого соединения уже HTTP-запрос, чтобы получить веб-страницу. Даже крошечный HTTP-запрос требует времени для отправки - большего, чем начальное установление TCP соединения. Потом еще надо будет отправить клиенту сформированную вам веб-страницу. Если в этот момент к вам придут другие клиенты, они только установят на уровне операционной системы TCP соединения, и будут стоять в очереди, ждать, когда осободится ваш обработчик. Который, в свою очередь, просто ждет завершения ввода-вывода операционной системой.
Очевидно, что так никто не работает.
Операционная система умеет эффективно выполнять много процессов ввода-вывода параллельно, нам надо только суметь загрузить ее этой работой. И заниматься другими задачами, пока она их выполняет.
Кроме того, возможность не ожидать, пока особо массивная страница отдается какому-то клиенту (и который пнимает, что запросил много и готов ждать), позволяет не затормаживать обслуживание тех клиентов, кто запросил небольшие страницы, и поэтому совсем не ожидает, что ответ получит очень нескоро, только когда мы отдадим большую страницу другому клиенту, о котором он не знает и не хочет ничего знать.
Много вычислений
Нам надо посчитать что-то вычислительно сложное. Считать это последователно долго. Хочется использовать полную мощность современного компьютера, в котором, как правило не один процессор.
Фоновая работа
Допустим, у нас веб-сервер, показывающий прогноз погоды. Но раз в 10 минут нам надо получить данные от поставщика данных. А потом, может и обработать. Т.е. нам надо регулярно делать что-то, что занимает много времени, либо потому что там большой ввод-вывод, либо потому что надо что-то долго считать. Нам не так уж важно сделать это быстро, но совершенно немыслимо прерывать на это время работу сайта - он должен продолжать оперативно обслуживать клиентов.
Методики решения
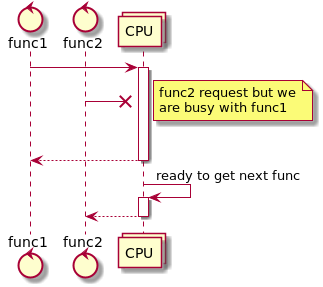
На первой картинке у нас показана ситуация до того, как мы выбрали способ выполнять код не синхронно. Мы выполняем его последовательно. В результате, если нам понадобилось выполнить новую задачу, когда мы заняты предыдущей, новая задача ждет в очереди.
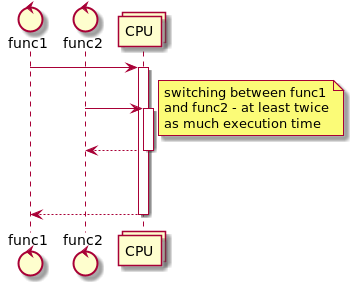
На второй картинке мы псевдо-параллельно выполняем обе функции, делая поочередно небольшой кусочек каждой из них. Поскольку вторая функция требует меньше времени, мы ответим на нее быстрее, чем на первую. В итоге мы быстрее ответим на вторую функцию, хотя и не сможем обработать больше функций.
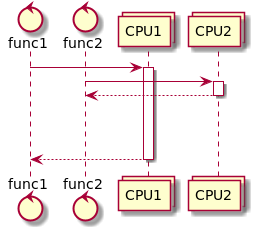
Как именно распилить функции на кусочки рассказывается в следующем разделе этой статьи. Как правило, все способы разрезания функций на кусочки также позволяют в периоды простоя не тратить на простаивающие функции ресурсы. Поэтому, если в момент прихода второй функции мы ждем чего-то для первой, то мы обработам вторую так же быстро, как если бы выполняли только ее. И наша система сможет выполнять больше функций, так же как на следующей иллюстрации. Если же простоев нет, то из-за переключений мы потратим на вторую функцию больше времени, чем при последовательном выполнении, но зато ответим на нее быстрее, чем закончим обработку первой.
На третьей картинке мы задействовали два процессора, поэтому можем обработать больше функций за единицу времени, и быстрее ответить на каждую из них.
Про Python GIL
Конкретно для интерпретатора CPython реализация не синхронного выполнения усложняется имеющимся в нем Global Interpreter Lock (GIL). Который, не позволяет интерпретатору работать параллельно в разных нитях (threads).
GIL существует потому, что сам интерпретатор не потокобезопасен. В принципе, можно было бы устранить GIL, но тогда это сделало бы развитие интерпретатора более трудоемким - при его разработке придется затрачивать немалые усилия на обеспечения безопасности при многопоточности. И заметно сказалось бы на производительности однопоточных приложений (см. краткое пояснение в wikipedia).
GIL может сниматься C-кодом. Также он обычно снимается, когда системные библиотеки Python выполняют ввод-вывод.
Поэтому, например, выполнять вычисления NumPy, или ждать завершения ввода-вывода быстрее в нескольких нитях, чем в одной. Поскольку при этом заметную часть времени GIL будет снят.
Но несколько нитей не дадут никакого выигрыша, если выполнять в них только Python-код. Точнее, будет даже медленнее, из-за накладных расходов на старт нитей.
GIL отсутствует в ряде альтернативных интерпретаторов Python (Jython, IronPython). Существует также специальная версия PyPy.
Способы несинхронного выполнения кода
Все описаные ниже способы решают проблему как параллельного выполнения - быстрый ответ на короткие функции, так и эффективное использование периодов простоя - не тратится время на ожидающие ввода-вывода функции.
Много процессов операционной системы
Самый простой и древний способ.
Запуск нашей программы нужное число раз и обеспечение взаимодействия между этими экземплярами (которые могут делать одно и тоже, а могут и отличаться). Нет никакого пересечения по памяти или общим переменным, все идеально изолировано.
Но если нам надо запускать тысячи таких процессов, то это будет крайне неэффективная работа операционной системы. Не говоря уже о том, что у вас вряд ли хватит оперативной памяти на запуск такого количества интерпретаторов Python.
В Python есть очень удобный модуль multiprocessing Позволяющий в несколько строк, независимо от операционной системы, запустить функции в параллельных процессах.
import multiprocessing as mp
import time
def f(name, timeout, queue):
time.sleep(timeout)
print('hello', name)
queue.put(name + ' done!')
queue = mp.SimpleQueue() # queue for communicating with the processes we will spawn
bob = mp.Process(target=f, args=('bob', 0.3, queue))
bob.start() # start the process
alice = mp.Process(target=f, args=('alice', 0.1, queue))
alice.start() # start the process
# wait for processes to complete
bob.join()
alice.join()
# print results from intercommunication object
for result in iter(queue.get, None):
print(result)hello alice
hello bob
alice done!
bob done!
При необходимости можно использовать multiprocessing в asyncio
Свойства
Делегируем задачу распараллеливания выполнения операционной системе.
Сейчас операционные системы используют вытесняющую многозадачность - процессы получают для работы небольшие интервалы времени, а далее контекст переключается на следующий в очереди планировщика процесс. Контекст переключается очень эффективно, без заметных затрат времени. И, конечно, если в системе есть несколько процессоров, то операционная система эффективно использует все.
Плюсы
- Распараллеливанием ресурсов занимается операционная система, умеющая это делать эффективно.
- Абсолютная изоляция. Нет никакого риска испортить состояние объектов, потому, что общих объектов, и даже общего интерпретатора, вообще нет.
- Нет Python GIL.
Минусы
- Высокие накладные расходы на запуск параллельного процесса.
- Параллельные процессы потребляют много оперативной памяти и ресурсов операционной системы.
- Переключение процессов современные операционные системы выполняют очень эффективно, но это все же один из самых дорогих способов переключения.
- Не простое и не дешевое межпроцессное взаимодействие. Модуль multiprocessing предоставляет нам набор очень удобных инструментов для того чтобы скрыть сложность этого взаимодействия. Но это не снижает его реальную стоимость.
Области и особенности применения
- По процессу на процессор, если речь о вычислительно тяжелых функциях
- Или разумное, небольшое, количество процессов, чтобы эффективно использовать время ожидания ввода-вывода или каких-то событий, по которым надо выполнить функции в этих процессах.
- Логически и по реализации существенно изолированные задачи, которые надо выполнять параллельно с основным процессом. И которые не хочется переписывать и отлаживать для стабильной работы в многопоточной или асинхронной среде.
Параллельное выполнение в нитях (threads)
Интерфейс выглядит похоже на интерфейс для multiprocessing
import threading
import time
import queue
def f(name, timeout, queue):
time.sleep(timeout)
print('hello', name)
queue.put(name + ' done!')
q = queue.Queue() # thread-safe queue
bob = threading.Thread(target=f, args=('bob', 0.3, q))
bob.start() # start the thread
alice = threading.Thread(target=f, args=('alice', 0.1, q))
alice.start() # start the thread
# wait for threads to complete
bob.join()
alice.join()
# print results from intercommunication object
for result in iter(q.get, None):
print(result)hello alice
hello bob
alice done!
bob done!
Свойства
Строго говоря, как и в предыдущем случае, мы делегируем задачу операционной системе. Именно она планирует выполнение нитей.
Плюсы
- Если обеспечивается принцип “каждая нить на своем процессоре”, то получаем максимально приближенное к железу решение, позволяющее максмально эффективно использовать ресурсы.
- Один из самых старых способов, поэтому для него наработано море методик и документации.
Минусы
- Запуск нитей существенно дешевле, чем процессов, но не супер-дешевый.
- Переключение достаточно эффективно но не существенно дешевле, чем в способе переключения процессов.
- Нельзя запускать нити тысячами - в таком случае операционная система будет тратить больше времени на переключением между ними, чем на полезную работу.
- Способ знаменит неисчислимым количеством способов отстрелить себе ногу. Нужна очень высокая квалификация для написания стабильного и эффективного решения. Отладка крайне сложна. Поиск дефектов требует сложного тестирования.
- Python GIL приводит к тому, что выполнение собственно Python кода не происходит параллельно в разных нитях.
Области и особенности применения
- Фоновая работа или эффективное использование ожидания ввода вывода.
- Для относительно небольшого числа функций.
- Желательно, чтобы функции требовали минимального межвзаимодействия, иначе реализация и отладка будет очень непростой.
Зеленые потоки и asynio coroutines
Кооперативная многозадачность.
Имеется цикл выполнения всех зеленых потоков, или coroutines.
Цикл выполнения последовательно берет очередной из ожидающих выполнения зеленых потоков/coroutine и
отдает ему управление.
Если зеленый поток/coroutine в ожидании ввода-вывода или какого-то события, то мы его пропускаем и
не тратим пока на него время.
Вся магия в двух моментах.
Во-1х зеленые потоки/coroutines должны уметь сами отдавать управление назад циклу выполнения,
чтобы “дать подышать” другим зеленым потокам/coroutines.
Отсюда и название “кооперативная многозадачность” - все это работает до тех пор,
пока все соблюдают правила. Если кто-то захватит управление, и не будет его отдавать, то получим
традиционное синхронное выполнение.
Во-2х зеленые потоки/coroutines должны явно сообщать циклу выполнения, что они чего-то ожидают.
Различие между зелеными потоками и asyncio только в деталях реализации.
А также в том, что asyncio является официальным решением для Python, и все основные библиотеки на
него переползают.
Зеленые потоки
Один из вариантов реализации в Python - gevent.
В основе лежит monkey patching, который преобразует основные библиотеки для ввода/вывода так, что
при обращении к ним реально управление передается циклу выполнения.
Например, чтобы urllib начал использовать подмененный socket и тем самым начал сотрудничать
с циклом выполнения:
from gevent import monkey
monkey.patch_socket()
import urllib3
Теперь используя вроде бы стандартный urllib наш никак более не измененный код будет добровольно,
хотя и незаметно для себя, давать возможность циклу выполнения выполнить другие зеленые потоки в
те моменты, когда запрашивает у urllib что-то, требующее длительного ожидания.
Важно вначале выполнить monkey patching, и только после этого импортировать пропатченный модуль.
import gevent
from gevent import monkey; monkey.patch_all()
import time
def f(name, timeout):
time.sleep(timeout)
print('hello', name)
return name + ' done!'
bob = gevent.spawn(f, 'bob', 0.3)
bob.start() # start the greenlet
alice = gevent.spawn(f, 'alice', 0.1)
alice.start() # start the greenlet
# wait for greenlets to complete
bob.join()
alice.join()
# print results
print(bob.value)
print(alice.value)hello alice
hello bob
bob done!
alice done!
В этом примере мы пропатчили time.sleep. Если убрать monkey.patch_all() то time.sleep будет
блокировать выполнение, и порядок выдачи изменится на:
hello bob
hello alice
bob done!
alice done!
В библиотеке gevent имеется gevent.sleep, и если бы мы его использовали, то не нужно было бы
патчить time.
Но я хотел продемонстрировать возможность превратить в “зеленый поток” любой код.
А также всю возникающую из-за этого неочевидность и сложность отладки - код выглядит синхронным,
попробуй понять, асинхронно он выполняется, или нет.
Плюсы
- Не надо существенно раскрашивать
async/await, как вasyncio, код зеленого потока. - Дешевое переключение между потоками.
- Потоков может быть много.
- Накладные расходы невысоки.
Минусы
Monkey patchingнеочевиден, поэтому даже при большом опыте вы будете очень приближенно понимать, что происходит в приложении. И оптимизация работы станет увлекательным научным приключением.
Области и особенности применения
Можно попробовать применить для большого объема унаследованного кода, который не предполагал асинхронность.
Есть риск надолго завязнуть в сложной отладке и так и не получить реально несинхронного выполнения, но зато при успехе экономим время на переписывании старого кода.
Asyncio
Стандарт для Python. Имеет специальные ключевые слова в языке.
import asyncio
async def f(name, timeout):
await asyncio.sleep(timeout)
print('hello', name)
return name + ' done!'
async def main():
bob = asyncio.create_task(f('bob', 0.3)) # start the coroutine
alice = asyncio.create_task(f('alice', 0.1)) # start the coroutine
# wait for coroutines to complete
print(await bob)
print(await alice)
asyncio.run(main()) # implicitly starts the loophello alice
hello bob
bob done!
alice done!
Плюсы
- В полном соответствии с Python принципами “явное лучше неявного” - полная прозрачность происходящего, упрощающая дальнейшее сопровождение приложений.
- Дешевое переключение между потоками.
- Потоков может быть много.
- Накладные расходы невысоки.
- В сочетании с отсутствие
monkey patchingполучаем достаточно простое логически решение. Которое на порядок проще писать и отлаживать, чем multy threading.
Минусы
Надо существенно изменять исходные код. После чего его использование в синхронном режиме, хотя и вполне возможно, но уже довольгно громоздко и менее эффективно (придется все равно стартовать цикл обработки).
Области и особенности применения
Не стоит использовать asyncio, если у используемых вами библиотек ввода/вывода нет
asycnio вариантов. Такие варианты сейчас появились почти для всего, но если вам не уйти от
использования не поддерживаемой библиотеки, для которой никому не понадобилось делать asyncio вариант,
возможно, рациональнее для начала попробовать сделать monkey patching, чем тратить много усилий на
создание asyncio версии своими силами.
В новом коде рекомендуется использовать именно asyncio.
Вполне решаемо совмещение зеленых потоков и asyncio - тем или иным образом надо решить
вопрос использования единого цикла выполнени для обеих библиотек.
Call-back hell
Для полноты упомяну js-way. Мы можем при вызове ввода-вывода указывать функции, которые после ввода-вывода надо будет вызвать. И после этого продолжать выполнение нашей программы.
Очевидно, что при этом приложение становится конечным автоматом. Вы пишете не последовательный код выполнения программы, а море обработчиков всевозможных событий. Которые, зачастую, логически совсем не выглядят событием (скажем, завершение открытия файла).
В принципе, несложный интерфейс пользователя так можно реализовать. Но как только нам надо сделать сложную обработку, мы получим очень запутанное приложение.
Поскольку callback это про способ взаимодействия с coroutines, чтобы его продемонстрировать я
взял asyncio.
Пример получился не страшным. Чтобы понять, во что в итоге выльется такой дизайн, вам надо далее
представить, что после получения результатов от bob и alice вам надо далее что-то с ними сделать.
Но вы уже не можете это описать как последователность инструкций - вам надо в обработчике on_result
понять, что все нужные результаты уже получены и далее куда-то передать управление. А там будет
очередной разрыв процесса выполнения, когда вам потребуется ждать другие coroutines. И порой это
будет вложенным процессом. В итоге приложение будет состоять из большого числа сложно связанных
функций, и из кода будет трудно понять последовательность их выполнения.
import asyncio
async def f(name, timeout, on_result):
await asyncio.sleep(timeout)
print('hello', name)
on_result(name + ' done!')
def on_result(msg):
print(msg)
async def main():
bob = asyncio.create_task(f('bob', 0.3, on_result)) # start the coroutine
alice = asyncio.create_task(f('alice', 0.1, on_result)) # start the coroutine
# wait for coroutines to complete
await bob
await alice
asyncio.run(main()) # implicitly starts the loophello alice
hello bob
bob done!
alice done!
Циклы выполнения на libuv и прочие
В описанном выше я не упоминал, как именно цикл выполнения понимает, что операционная система,
например, закончила считывание файла, и, значит, управление можно опять давать той coroutine что
этого ожидала.
Конкретные реализации не только существенно зависят от операционных систем. В рамках каждой операционной системы может быть несколько способов этого сделать.
Поэтому имеется несколько вариантов реализации цикла выполнения.
Понять, какой из них лучше, и для чего - нетривиальное исследование.
Сложность связана с тем, что эффективность надо измерять в реальных условиях.
А реальный ввод-вывод очень сложно сделать повторяемым.
При этом его задержки должны быть достаточно существенными, чтобы продемонстривать
эффективность или неэффективность. На фоне этих задержек не просто поймать вклад
в производительность собственно цикла выполнения.
Комбинации
При необходимости можно комбинировать multiprocessing и asyncio