Non-sequential Python

Introduction
Modern sotware developers has a lot of options to perform application logic in non-sequential way.
But you have to understand which option is the best for the task at your hand.
I wrote this text to give you the information to choose.
Why we need non-sequential code
Massive IO (input/output)
We use computers with separate subsystems for fast (and expensive) and slow (and cheap) memory - RAM (“memory”) and disk (even SSD).
Also we mean ‘network’ when we speak about IO.
So suppose you wrote web-server and you can handle requests pretty fast but after that you need to send responce by network and that will take 100x times more.
And during processing for example you spent 1us to process and 1ms to wait for data from DB.
The problem that when you wait for DB or network you do not serve other client requests. And for sure you can serve them - you have plenty of CPU power and even DB and CPU - they are more effective if you have a number of requests in parallel.
Если в этот момент к вам придут другие клиенты, они только установят на уровне операционной системы TCP соединения, и будут стоять в очереди, ждать, когда осободится ваш обработчик. Который, в свою очередь, просто ждет завершения ввода-вывода операционной системой.
Complex calculations
For example machine learning tasks need a lot of CPU power.
And here we have just opposite situation as described above. We use all our CPU power and would like to use even more (for example second CPU on the machine) just to serve client request faster.
Daemons
For example our web-server shows weather forecast. And have to download new forecast each hour.
Downloading of new forecast is long procedure and we cannot stop serving current requests. And we even do not need to dounload the new forecast as fast as possible - we can do that slow but important thing do not slow down client requests that we serve at the moment of downloading new forecast.
Non-sequential options
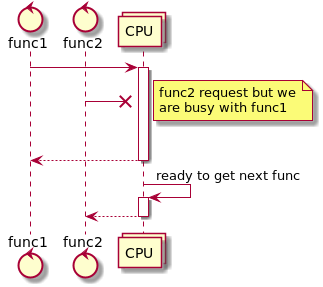
1st picture - sequential way. Tasks are served sequentially, one at a time. 2nd task will wait for the end of 1st task.
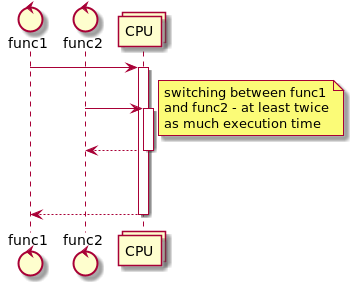
2nd picture pseudo=parallel - we perfome tasks by small peaces. So we will serve small tasks faster. And we will serve 2nd task faster than 1st. But of cause by the cost of slowing down 1st task.
How to do that in practice?
Operating system do that by the help of CPU - it gives each process small chunk of time.
Inside process we can for example use system call for that. When one application ‘green thread’ do some system call we intercept it and after calling system we give control to other application ‘green thread’. And when it do system call do the same. And again ang again. the is additional advantage that most system calls mean IO - application ‘green thread’in any case have to wait system to do some IO (read file, send packet to network etc). And we use this ‘natural pause’ to execute another application ‘green thread’’’
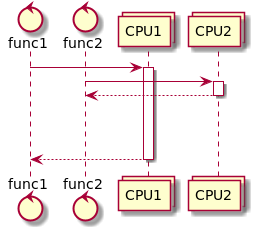
3rd picture we use two CPU so we really execute in parallel.
Python GIL
CPython in general cannot use multi-threading effectively due to Global Interpreter Lock (GIL).
GIL in Python exists just by historical reasons and because CPython developers want to interpret existing huge Python code most effectively.
To remove GIL you need to use some multi-threading mechanisms even for single-thread code (because in gerenal you cannot tell if it’s single- or multi-threaded). And that will slow down nearly all Python application. too high cost (https://en.wikipedia.org/wiki/Global_interpreter_lock).
In fact Python IO libraries and C-code for example in NymPy unlock GIL so multi-threading work good in code with a lot of IO or with written on C libraries.
But there is no sense in multi-threading for just a Python code - you will get even wosrt performance in comparison with single-thread (and too complicated code as well).
BTW there are a number of other (not CPython) Python interpreters without GIL (Jython, IronPython). PyPy fork.
Ok with theory but how to do that in practice
Below are a number of way to have non-sequential Python code.
Multi-processing
Just have running as many our application instances as we want. And let the OS do all the dirty task in managing resources between this processes.
Of cause you would not run hundreds of instances - too heavy memory overhead and CPU resources waste due to switching between processed.
And all the instances are separate - they can communicate but this is not very efficient.
Example of multiprocessing usage:
import multiprocessing as mp
import time
def f(name, timeout, queue):
time.sleep(timeout)
print('hello', name)
queue.put(name + ' done!')
queue = mp.SimpleQueue() # queue for communicating with the processes we will spawn
bob = mp.Process(target=f, args=('bob', 0.3, queue))
bob.start() # start the process
alice = mp.Process(target=f, args=('alice', 0.1, queue))
alice.start() # start the process
# wait for processes to complete
bob.join()
alice.join()
# print results from intercommunication object
for result in iter(queue.get, None):
print(result)hello alice
hello bob
alice done!
bob done!
And you can even use multiprocessing in asyncio application
Properties
Let OS manage resources between our processes.
Pluses
- OS manage resourses very well (for a reasonable number of processes).
- Absolute isolation. Very simple logic (if you do not need inter-process communications)
- No Python GIL.
Minuses
- High cost to fork and keep running separate OS processes.
- High memory consumption (each process has separate Python interpreter).
- High cost switching between processes (this is harware based but in any case we need to do a lot of things).
- Bad choice if you need a lot of communication between your “application threads”. There are a number of very convenient tools in Python multi-processing module but in any case this is expensive inter-communications.
Where to use
- We need to use all CPU for heavy computation - run at least as many processes as number of CPU
- Effectively use wait for IO - just run a small number of processes so when one whit others will work.
- Background work without a lot of communications with main application logic. Run separate process for each backgroun task. Conside usage of appropriate tool like Celery.
Multi-threading
Ancient way from our software engineering ancestors.
In python API is the same as for multi-processing.
import threading
import time
import queue
def f(name, timeout, queue):
time.sleep(timeout)
print('hello', name)
queue.put(name + ' done!')
q = queue.Queue() # thread-safe queue
bob = threading.Thread(target=f, args=('bob', 0.3, q))
bob.start() # start the thread
alice = threading.Thread(target=f, args=('alice', 0.1, q))
alice.start() # start the thread
# wait for threads to complete
bob.join()
alice.join()
# print results from intercommunication object
for result in iter(q.get, None):
print(result)hello alice
hello bob
alice done!
bob done!
Properties
As in multy-processing we delegate CPU sharing task to OS. But now we have more fine-grade control.
Pluses
- The most efficient way to use all CPU.
- A lot of knowlidge and documentation - this way is mostly reaserched in many years of usage.
Minuses
- Launching thread is cheaper than launching process, but still pretty expensive.
- The same about switching between threads.
- You cannot have thousands of threads. Ok you can if you want to but in this case CPU mostly will work for inter-thread switching and will have very litle time for useful work.
- Very complex in implementation. You have to read a lot and spend years in practicing it before you fill confident and can write stable applications.
- Because of Python GIL this way good only for waiting for IO and for non-python libraries.
Where to use
- Background tasks and waiting for IO.
- Small amount of parallel threads.
- Simple intre-thread communication if you do not wont spent in debugging all your life.
Green threads and asynio coroutines
Cooperative multi-tasking.
All green threads are executed in execution loop as coroutines.
Execution loop take green threads/coroutines one by one and execute them.
When green thread/coroutine stop execution to wait for IO or some
event, execution loop gets nest green thread.
All this works just because green threads/coroutines stops at some moments
by themself and gave control back to execution loop which start next
green thread.
So this is “cooperative multi-threading” and works only if all green threads
are polite and gave control back to execution loop from time to time.
In fact green threads just old version of the same technic that now we call
asyncio.
But now asyncio is official standard for Python and a lot of libraries use it.
Green threads
There are a number of implementations. One example -gevent.
It uses monkey patching.
This is a way how to change system libraries so they will catch
control on all IO calls and call execution loop.
For example if we want urllib to use patched socket and cooperate
with execution loop:
from gevent import monkey
monkey.patch_socket()
import urllib3
From this point urllib will send control to execution loop each time
somebody wait for network IO.
So just do monkey patching and after that you can use the patched library
just as usual.
import gevent
from gevent import monkey; monkey.patch_all()
import time
def f(name, timeout):
time.sleep(timeout)
print('hello', name)
return name + ' done!'
bob = gevent.spawn(f, 'bob', 0.3)
bob.start() # start the greenlet
alice = gevent.spawn(f, 'alice', 0.1)
alice.start() # start the greenlet
# wait for greenlets to complete
bob.join()
alice.join()
# print results
print(bob.value)
print(alice.value)hello alice
hello bob
bob done!
alice done!
In this example we patched time.sleep.
If you comment monkey.patch_all() then output will be different:
hello bob
hello alice
bob done!
alice done!
In fact there is special gevent.sleep in gevent so no need in
patchingtime.
But my intension was to demonstrate the technic. Also you can see how is this
implicite and had to see. Looking at the code you have no idea that in fact
it can stop execution and execute another code.
Pluses
- We don’t complicated our code with explicite
async/await, as withasyncio - Cheap switching between
green therads(actually zero cost) - We can have very large amount of
green threads - No cost overhead
Minuses
Monkey patchingimplicite and even big experience won’t gove you good understanding how you code actually works.
Where to use
Legacy projects.
In worst case scenario you just could not make it work, but in the best case it just
magically became multi-thread at nearly zero efforts from you.
Asyncio
Python standard. Special operator in the language.
import asyncio
async def f(name, timeout):
await asyncio.sleep(timeout)
print('hello', name)
return name + ' done!'
async def main():
bob = asyncio.create_task(f('bob', 0.3)) # start the coroutine
alice = asyncio.create_task(f('alice', 0.1)) # start the coroutine
# wait for coroutines to complete
print(await bob)
print(await alice)
asyncio.run(main()) # implicitly starts the loophello alice
hello bob
bob done!
alice done!
Pluses
- As in Python motto “explicite is better than implicite”. Easy to understand and to debug.
- Cheap switching
- We can have very large amount of
coroutines - No cost overhead
Minuses
You have a lot of asyn/await in you code and that complicate application logic.
And you will have async code that should be used as async.
Where to use
All libraries that you use have asyncio version.
Now this is Pythonic standard so with high probability this is your case.
Call-back hell
Just to have a whole picture I want to say a couple of words about js-way.
In each potentially async function you specify functions that will be called after
complition of this function.
Obviously after that you application is a some kind of finite-state machine.
You have a lot of ‘handler’ instead of some ‘logic flow’.
In fact this is good for UI which is naturally event-driven.
But this is just spagetty-code for other purposes.
I wrote some example - see it below.
I kept it simple but you need just a little imagination to understand what monster will you have if you continue to write application in this way.
At the end of the day you will have a mess of handler without any understanding how they are interconnected.
import asyncio
async def f(name, timeout, on_result):
await asyncio.sleep(timeout)
print('hello', name)
on_result(name + ' done!')
def on_result(msg):
print(msg)
async def main():
bob = asyncio.create_task(f('bob', 0.3, on_result)) # start the coroutine
alice = asyncio.create_task(f('alice', 0.1, on_result)) # start the coroutine
# wait for coroutines to complete
await bob
await alice
asyncio.run(main()) # implicitly starts the loophello alice
hello bob
bob done!
alice done!
libuv and others
In fact for any execution loop tricky part - how to understand that we got
data we was waiting for and have to contie this coroutine.
From application logic point of view this is irrevalent.
But different execution loop implementation will have different performance
for different situations and in different OS.
There are a lot of execution loop implementations.
To compare them - very complicated task that cannot be done ‘in-general’,
results heavily depends on application and resources it uses.
Combine
In some cases it’s convenient to combine different technics. For example you can write asyncio application with multiprocessing